
在软件开发的过程中,我们越来越多地接触到“分布式系统”这一概念。
但是,很多人对其具体概念并不熟悉,导致学习起来很混乱。
既然 @知识库 进行了提问,我们就通过本文介绍分布式系统的基本概念,以及其解决了哪些问题,带来了什么问题。
1 什么是分布式系统?
首先,在学术界,对分布式系统的定义并不统一。
例如,有的学者将分布式系统定义为“一个其硬件或软件组件分布在联网的计算机上,组件之间通过传递消息进行通信和动作协调的系统”;有的学者将分布式系统定义为“若干独立计算机的集合,这些计算机对于用户来说就像是单个相关系统”。
显然,上述定义都可以涵盖分布式系统,但却又过于宽泛和模糊,与软件开发者日常讨论的分布式系统的概念相去甚远。
在工程界,分布式系统的概念也是模糊的。
例如我们会说ZooKeeper是分布式系统,也会说微服务系统是分布式系统。显然,这两类系统的差别很大。
那分布式系统到底是什么呢?我们在讨论分布式系统时,在讨论什么呢?
其实我们可以从最简单的单体应用系统出发,将系统划分为很多小的类别,然后给出分布式系统的界限。不过,这需要很大的篇幅。在这里我们就不划分了,直接给出结论。
那如何去界定工程中的分布式系统?其标准是:
系统是否使用多个一致的信息池。
这里解释一下概念:
如果系统使用多个一致的信息池,那它就是分布式系统;否则就不是。
或许稍有难以理解,不过放心,我们下面会通过示例帮助大家理解这一定义。
另外还要说明,在以上的定义中,我们不需要关心节点是同质的还是异质的。即分布式系统中的各个节点可以运行完全相同的程序,也可以运行不同的程序。这不是区分分布式系统的关键。
接下来我们举出几种在工程中常见的满足和不满足分布式系统的示例。
1.1 几种不满足的示例
例如,有时候我们会将节点的代码部署到多个机器上,然后让它们连接同一个数据库,组成节点集群。这样的系统如下所示。
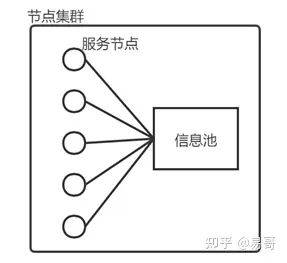
这种节点集群的好处是实现简单、能够应对部分服务节点宕机的状况。
不过这种系统不是分布式系统,只能算是节点集群。因为它只存在唯一的信息池。这也是其软肋所在,该信息池宕机,则系统宕机。
例如,有时我们会为不同的用户分配不同的服务节点。每个节点都有独立的信息池,保存该用户的信息。如果该节点宕机,便无法服务该用户。
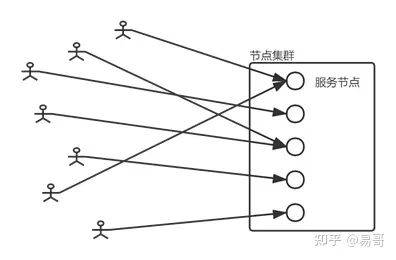
这种集群的典型特点就是各个节点是完全隔离的。这些节点运行同样的代码,有着同样的配置,然而却保存了不同用户的上下文信息,各自服务自身对应的用户。
这种也不是分布式系统,因为各个信息池并不一致。一个节点上的数据发生变化时,另一个并不需要配合变动,各个节点的信息是独立的。
所以,平时我们说的许多以“集群”结尾的系统,并不一定是分布式系统。
1.2 几种满足的示例
我们在上文中说,“会说ZooKeeper是分布式系统,也会说微服务系统是分布式系统”。是的,这两种都是分布式系统。
ZooKeeper集群是一个分布式系统,其各个节点运行的程序、配置是完全相同的(节点中Leader、Follower、Learner的角色划分只是程序运行过程中的中间变量),因此Zookeeper中的节点都是同质节点。而且,每个节点都用内存作为信息池保存了znode数据,当ZooKeeper上存储的数据发生变化时,各个节点的数据也会发生变化。因此,ZooKeeper集群是一个由同质节点组成的分布式系统。
包含订单服务、库存服务、支付服务的电商应用是一个分布式系统。该系统还可以继续细分,如果所有服务只能作为应用的一部分联合起来对外提供服务,那这是一个分布式应用;如果每个服务既可以独立对外提供服务也可以联合对外提供服务,则这是一个微服务应用。但它们都属于分布式系统。该分布式系统中的节点可能是异质的(订单服务节点和库存服务节点的代码、配置等并不相同)。
所以,平时我们说的“微服务”等系统,一般是分布式系统。
2 分布式系统解决了什么问题?
分布式系统的搭建并不简单,要涉及理论、实践、工程等领域的众多知识。然而,它仍然得到了极为广泛的应用,是因为它有着下面的优势。
2.1 降低应用成本
能够降低应用的实施成本是分布式系统产生和发展的最初动力。
对于单体应用而言,当应用负担的功能、承载的并发量和数据量逐渐提升时,应用对硬件的要求也逐步提高。这时只能升级应用的硬件设施,采用运算能力、存储能力、IO能力更高的计算机,这类计算机通常被称为大型机。然而,大型机的购买和维护费用十分高昂。
分布式系统的出现使得单体应用可以被拆分为小应用部署到小型服务器集群上,以此来实现高并发、大数据、多功能。这大大降低了应用的实施成本。
2.2 增强应用可用性
单体应用存在单点故障风险。应用节点运行出现异常意味着整个应用不可用。而分布式系统则避免了这一问题。
分布式系统在工作时由众多节点共同对外提供服务,其中的一个节点出现故障后,其请求会被其他节点分摊。同时,应用可以在运行过程中根据负载情况动态增删节点,极大地提升了应用的可用性。
2.3 提升应用性能
单体应用所能承载的容量、并发数是有限的,当数据量过大时则会产生性能瓶颈。分布式系统可以通过众多节点来分担容量压力和并发压力,有利于提升了整个应用的性能。
2.4 降低了开发与维护难度
单体应用中糅合了众多功能模块,这些功能模块互相调用,交织耦合在一起,共同组成了一个庞大复杂的整体。任何一个功能模块的升级改造都可能会对其他模块造成影响。这增加了开发和维护的难度。
在分布式系统中,所有的功能模块都分离开来作为独立的应用节点存在,实现了模块化。这降低了功能模块之间的耦合,只要我们维持应用节点的原有对外接口不变,便可以安全地增加新接口或者优化内部实现。
模块化的实现也增加了模块复用的可能性。并且,各个模块可以采用并行的方式进行开发,提升了开发的效率。
在升级部署时,单体应用需要对整个应用进行重新发布,而分布式系统则只需要重新发布发生变化的模块化应用,降低了升级部署失败的风险,提升了应用升级部署的速度。
3 分布式系统的问题
当然,实施分布式系统也要面临很多的问题。下面是一些非常典型的问题。
3.1 一致性问题
分布式一致性问题是分布式系统面临的最为突出的问题。
在单体应用中,应用本身只有一个节点,外部的任何变更请求都由该节点直接处理,并在接下来向外给出最新的结果。
在分布式系统中,应用包括多个节点。外部的变更请求会落到应用的任意一个节点上,随后,外部的读取请求可能会落到其他的节点上。这样,外部可能读取到一个变更前的结果。即出现了读写不一致。
为了避免读写不一致,分布式系统需要及时地将一个节点上的变更反映到所有节点上,即实现分布式系统的一致性。然而实现分布式系统的一致性是一个涉及理论、实践的十分复杂的过程,稍有不慎便会对应用的性能造成影响。
3.2 节点发现问题
单体应用只有一个节点,这个节点的地址便是整个应用对外提供的服务地址。因此,提供服务的地址是静态的。
分布式系统包含众多节点,每一个节点都可以对外提供服务。而且应用集群中会发生节点的增删,这导致能够提供服务的节点是一个动态变化的集合。这使得我们需要设计一种机制来帮助调用方发现分布式系统中的可用节点,即解决节点发现问题。
3.3 节点调用问题
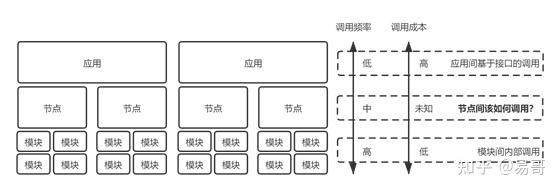
单体应用内部存在模块间的调用,这种调用发生在应用内,是高频的,但同时也是低成本的、高效的。
应用之间也会存在调用,常基于接口实现。这种调用是相对低频的,同时也是高成本的、低效的。
分布式系统内部的节点之间也会存在调用。这种调用由单体应用的模块间调用演化而来,其调用频率是相对较高的。但是,他们之间的调用已经无法通过应用的内部调用来实现,基于接口的调用则成本太高、效率太低。这时需要一种能够跨节点的、相对低成本和高效的方式来解决节点间的调用问题,这个问题如下图所示。
3.4 节点协作问题
单体应用的所有资源均由单一节点调用,不需要协作。但在分布式系统中,情况变得复杂起来。
例如,在一个同质节点组成的分布式系统中,一个定时汇总任务只需要应用中的某一个节点执行。但如果不采取特殊的机制进行约束,分布式系统中的各个节点会在指定时间同时执行任务,进而产生多份汇总结果。
异质节点组成的分布式系统中也会面临类似的问题。例如,分布式系统中的部分节点作为生产者,另外部分节点作为消费者。只有两类节点互相协作才能保证应用的生产、消费过程顺利展开。
如何让分布式系统中的各个节点进行协作,就是分布式系统面临的节点协作问题。



