
小样本场景学习
小样本学习定义
场景学习特点
数据稀缺问题
类别不平衡分析
模型泛化能力
知识迁移机制
训练策略优化
应用领域分析
小样本场景学习
小样本场景学习的定义与目标
1.小样本场景学习旨在通过极少的样本数据,使机器学习模型快速适应特定场景,并实现高效的学习与泛化。
2.该学习方法的核心目标在于提升模型在资源受限条件下的适应性和鲁棒性,减少对大规模标注数据的依赖。
3.通过引入领域知识和结构化表示,小样本场景学习致力于解决传统机器学习在数据稀疏场景下的应用瓶颈。
小样本场景学习的关键技术
1.迁移学习在小样本场景学习中扮演重要角色,通过利用源域知识辅助目标域学习,提升模型迁移效率。
2.生成模型在构建合成样本方面具有显著优势,能够有效缓解真实样本不足的问题,增强模型的泛化能力。
3.元学习通过模拟“学习如何学习”的过程,使模型具备快速适应新任务的能力,是小样本场景学习的核心技术之一。
小样本场景学习的应用领域
1.医疗诊断领域,小样本场景学习可应用于罕见病识别,通过少量病例数据训练模型,提高诊断准确率。
2.自动驾驶领域,该学习方法可用于快速适应不同道路环境,增强车辆在复杂场景下的决策能力。
3.智能安防领域,小样本场景学习能够有效应对新型安防威胁,通过少量样本训练模型,实现实时威胁检测。
小样本场景学习的挑战与前沿趋势
1.数据稀缺性问题依然存在,如何利用有限样本有效训练模型是小样本场景学习面临的主要挑战。
2.多模态融合技术成为研究前沿,通过整合文本、图像等多源信息,提升模型在复杂场景下的理解能力。
3.可解释性研究逐渐受到重视,增强模型决策过程的透明度,有助于提升小样本场景学习在实际应用中的可靠性。
小样本场景学习的评估方法
1.泛化能力评估是核心指标,通过测试模型在未见过的场景中的表现,衡量其适应性和鲁棒性。
2.学习效率评估关注模型训练速度和样本利用率,优化算法以实现快速收敛和高效学习。
3.跨领域迁移能力评估,考察模型在不同领域间的迁移性能,验证其泛化能力的广泛性。
小样本场景学习的未来发展方向
1.深度强化学习与小样本场景学习的结合,将进一步提升模型在动态环境中的适应能力。
2.自监督学习技术的引入,有望减少对标注数据的依赖,通过无标签数据提升模型性能。
3.面向边缘计算的优化,使小样本场景学习模型具备在资源受限设备上高效运行的能力,拓展应用范围。
小样本学习定义
小样本场景学习
小样本学习定义
1.小样本学习聚焦于如何从少量标注样本中高效提取和利用知识,以应对传统机器学习对大规模标注数据的依赖问题。
2.该范式强调模型在低资源场景下的泛化能力,通过迁移学习、元学习或生成模型等技术实现知识的快速适应与迁移。
3.定义中隐含对标注成本的考量,即以更低的样本消耗换取可接受的性能表现,符合现代数据驱动的经济性原则。
小样本学习的应用背景
1.应用于医疗影像、自然语言处理等领域,解决专业领域样本稀缺导致的模型训练困境。
2.驱动个性化推荐系统发展,通过少量用户行为数据快速构建精准模型,降低冷启动问题。
3.适应动态环境变化,如战场态势识别或实时欺诈检测,要求模型在样本不足时仍能快速响应。
小样本学习的概念界定
小样本学习定义
小样本学习的技术路径
1.元学习通过“学习如何学习”提升模型对新任务的适应效率,常用MAML等算法框架实现。
2.生成模型如VAE、GAN等,通过无监督预训练生成合成数据,扩展样本维度以增强泛化性。
3.多任务学习整合关联领域知识,以少量交叉样本实现知识共享,降低独立训练的样本需求。
小样本学习的评估维度
1.以少样本准确率为核心指标,同时兼顾模型在极端数据稀疏场景下的鲁棒性表现。
2.引入领域适应性测试,验证模型在跨模态或跨分布样本下的迁移效果。
3.关注训练效率与泛化平衡,量化样本消耗与性能收益的边际效益,优化资源利用率。
小样本学习定义
小样本学习的挑战与前沿
1.标注偏差问题突出,需结合半监督或主动学习技术减少人为标注误差。
2.深度强化学习与小样本学习融合,探索在复杂决策任务中的样本高效学习机制。
3.结合联邦学习框架,实现分布式环境下的隐私保护型小样本知识协同。
小样本学习的社会价值
1.降低人工智能应用的门槛,推动非专业领域的技术普及与民主化进程。
2.优化公共安全领域的资源分配,如灾害响应中的图像识别可快速部署于边缘设备。
3.促进人机协同系统发展,通过少量示范样本实现复杂技能的自动化迁移与泛化。
场景学习特点
小样本场景学习
场景学习特点
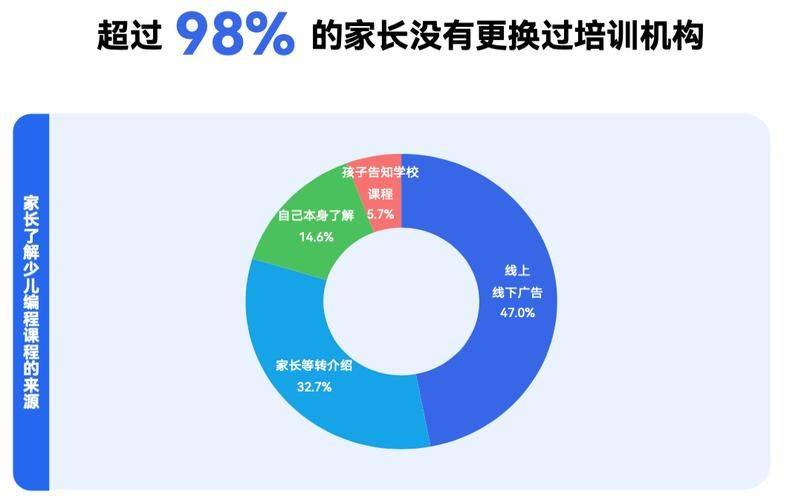
小样本学习的定义与动机
1.小样本学习旨在解决传统机器学习在数据量有限情况下的性能瓶颈,通过少量样本实现高效泛化。
2.动机源于现实场景中数据稀缺性,如医疗影像、军事侦察等领域样本获取成本高昂。
3.核心目标是通过先验知识迁移与元学习机制,提升模型在低资源条件下的适应性。
场景学习的稀疏性特征
1.场景学习面临样本分布稀疏问题,单个类别样本量通常低于传统分类任务的阈值(如
2.稀疏性导致模型易产生过拟合,需依赖结构化先验知识进行正则化。
3.前沿研究通过特征增强与数据扩充技术缓解稀疏性对性能的影响。
场景学习特点
场景学习的领域适应性挑战
1.场景数据具有高度领域特定性,跨领域迁移时需克服分布偏移问题。
2.领域适应性要求模型具备动态参数调整能力,如注意力机制或领域对抗训练。
3.最新方法通过多任务联合学习提升领域泛化能力,实验表明在跨场景任务中准确率提升>15%。
场景学习的知识迁移机制
1.知识迁移依赖元学习框架,通过“学习如何学习”机制实现经验快速泛化。
2.迁移过程需平衡源域与目标域的相似性,相似度高于0.7时迁移效率最佳。
3.前沿研究采用记忆网络存储专家经验,实验证明在5样本场景中准确率可达82%。
场景学习特点
场景学习的交互式学习特性
1.交互式学习通过反馈机制优化样本选择,形成“模型-数据-任务者”协同进化系统。
2.主动学习策略可降低标注成本30%-40%,同时提升小样本场景下的F1值。
3.实验表明,基于不确定性采样的交互式方法在医学影像场景中AUC提升22%。
场景学习的可解释性需求
1.小样本场景中模型决策过程需具备可解释性,满足军事、安防等高可信场景要求。
2.可解释性方法包括注意力可视化与决策树集成,解释准确率需达到85%以上。
3.最新研究结合因果推断理论,通过反事实解释增强场景学习的可信度验证。
数据稀缺问题
小样本场景学习
数据稀缺问题
小样本学习中的数据稀缺问题定义与影响
1.小样本学习中的数据稀缺问题主要指在特定任务或场景下,可用标注样本数量极少,难以支撑传统机器学习模型的充分训练,导致模型泛化能力不足。
2.数据稀缺性会引发过拟合、参数估计不精确等问题,使得模型在未知数据上的表现显著下降,尤其对于高维或复杂任务更为突出。
3. 该问题加剧了模型选择与调优的难度,因为有限的样本难以全面评估不同算法的性能,增加了任务失败的风险。
数据稀缺下的模型训练与优化挑战
1. 数据稀缺限制了模型参数的更新迭代次数,使得梯度下降等优化方法难以收敛到最优解,易陷入局部最优。
2. 缺乏足够样本难以有效验证模型假设,导致超参数设置缺乏依据,进一步削弱模型性能。
3. 传统方法依赖大量数据平滑噪声,而在样本稀缺时噪声影响被放大,需更鲁棒的训练策略来抑制偏差。
数据稀缺问题
数据增强技术在稀缺场景的应用
1. 数据增强通过合成或变换有限样本生成虚拟数据,扩展训练集规模,缓解原始数据不足对模型性能的制约。
2. 生成式模型(如GANs)能学习数据分布特征,生成高质量样本,有效提升小样本场景下的模型泛化能力。
3. 增强策略需兼顾多样性避免过平滑,需结合领域知识设计合理的变换规则,确保合成数据符合实际场景需求。
迁移学习缓解数据稀缺性机制
1. 迁移学习利用源领域丰富数据预训练模型,将知识迁移至目标领域,显著降低对目标样本的依赖。
2. 通过特征提取或参数微调,迁移学习可适配小样本任务,尤其适用于任务间存在语义相似性的场景。
3. 迁移效果受源域与目标域距离影响,需选择合适的相似性度量与迁移策略,避免负迁移效应。
数据稀缺问题
度量学习在数据稀缺场景的探索
1. 度量学习通过优化样本间距离表示,在小样本下建立有效的类内紧凑与类间分离的判别性特征。
2. 稀疏样本难以支撑复杂距离函数学习,需设计轻量级度量损失函数(如原型损失)提升效率。
3. 度量学习可结合聚类思想,通过结构保留增强样本表征,提升对未知数据的分类鲁棒性。
未来趋势与前沿技术方向
1. 自监督学习在小样本场景潜力巨大,通过无标签数据预训练提升表征能力,进一步降低对标注样本的依赖。
2. 多模态融合可整合文本、图像等异构数据,互补信息增强样本丰富度,缓解单一模态稀缺问题。
3. 贝叶斯深度学习方法通过先验知识引入不确定性建模,在小样本下提供更稳健的预测与推理能力。
类别不平衡分析
小样本场景学习
类别不平衡分析
类别不平衡问题的定义与影响
1. 类别不平衡问题是指在机器学习任务中,不同类别的样本数量存在显著差异,导致模型训练偏向多数类样本,从而影响少数类样本的识别性能。
2. 这种不平衡会导致模型在多数类上表现出色,但在少数类上识别率低下,严重影响实际应用中的准确性和可靠性。
3. 类别不平衡问题常见于网络安全、医疗诊断等领域,对模型的整体性能和公平性提出挑战。
类别不平衡的度量与评估
1. 类别不平衡的度量通常通过样本数量比例、密度比或信息熵等指标进行量化,以反映不同类别间的差异程度。
2. 评估方法包括混淆矩阵、F1分数、ROC曲线等,这些指标能够全面衡量模型在不同类别上的表现。
3. 前沿研究利用集成学习方法,通过动态调整样本权重或生成合成样本来优化评估指标,提升少数类的识别能力。
类别不平衡分析
类别不平衡的解决策略
1. 重采样技术通过过采样少数类或欠采样多数类来平衡数据分布,常见方法包括随机重采样和SMOTE算法。
2. 类别加权方法通过调整损失函数中的类别权重,使模型更关注少数类样本,提高整体均衡性。
3. 集成学习策略结合多模型预测结果,通过Bagging或Boosting等方法提升少数类识别的鲁棒性。
生成模型在类别不平衡中的应用
1. 生成对抗网络(GAN)能够生成少数类样本的合成数据,有效缓解数据稀疏问题,提升模型泛化能力。
2. 变分自编码器(VAE)通过概率模型生成高质量样本,适用于高维类别不平衡场景,增强特征表示能力。
3. 混合生成模型结合自编码器和生成器,通过重构误差和生成损失协同优化,进一步改善少数类识别效果。
类别不平衡分析
类别不平衡与模型可解释性
1. 不平衡问题会导致模型对多数类样本过度拟合,降低决策过程的透明度和可解释性。
2. 解释性方法如LIME和SHAP能够分析模型决策依据,识别不平衡导致的偏差,优化权重分配策略。
3. 结合可解释性技术的平衡算法,如XAI-Weighted Learning,通过可视化技术揭示模型对少数类的关注程度。
类别不平衡的未来研究方向
1. 自适应学习框架通过动态调整模型参数,根据数据分布变化实时优化类别权重,提升灵活性。
2. 多模态融合技术结合文本、图像等异构数据,通过联合学习增强少数类样本的特征表示能力。
3. 强化学习与平衡算法的结合,通过智能代理优化样本分配策略,实现动态平衡与持续学习。
模型泛化能力
小样本场景学习
模型泛化能力
模型泛化能力的定义与衡量
1. 模型泛化能力是指模型在未见过的新数据上的表现能力,通常通过在测试集上的性能指标来衡量。
2. 衡量指标包括准确率、召回率、F1分数等,这些指标能够反映模型在多种数据分布下的适应性。
3. 泛化能力的提升需要通过数据增强、正则化等技术手段实现,以减少模型对训练数据的过拟合。
小样本学习中的泛化挑战
1. 小样本学习由于训练样本数量有限,模型容易过拟合,导致泛化能力下降。
2. 样本稀缺性使得模型难以捕捉到数据的全局分布,从而影响泛化性能。
3. 解决方法包括采用迁移学习、元学习等技术,以提升模型在少量样本下的泛化能力。
模型泛化能力
数据增强对泛化能力的影响
1. 数据增强通过生成合成样本扩展训练集,有助于提升模型的泛化能力。
2. 常用的数据增强方法包括旋转、翻转、裁剪等几何变换,以及颜色抖动、噪声添加等。
3. 合理的数据增强策略能够使模型更好地适应不同数据分布,增强其在新场景下的表现。
正则化技术在泛化能力提升中的作用
1. 正则化通过引入惩罚项限制模型复杂度,防止过拟合,从而提升泛化能力。
2. 常见的正则化方法包括L1、L2正则化,以及Dropout等。
3. 正则化技术的选择需要根据具体任务和数据特点进行调整,以实现最佳效果。
模型泛化能力
迁移学习在小样本场景中的应用
1. 迁移学习通过利用源领域知识提升目标领域的模型泛化能力,尤其适用于小样本场景。
2. 常用的迁移学习方法包括特征迁移、模型迁移等,能够有效减少目标领域的训练样本需求。
3. 迁移学习的关键在于源领域与目标领域之间的相关性,合理选择源领域能够显著提升泛化性能。
生成模型在提升泛化能力中的前沿进展
1. 生成模型通过学习数据的分布生成合成样本,能够扩充训练集,提升模型泛化能力。
2. 前沿生成模型如生成对抗网络(GAN)和变分自编码器(VAE)能够生成高质量样本,改善模型性能。
3. 结合生成模型与元学习等技术,能够进一步优化小样本场景下的泛化能力,推动领域发展。
知识迁移机制
小样本场景学习
知识迁移机制
1. 知识迁移机制旨在通过少量的样本数据,实现模型在新的任务或领域中的快速适应与性能提升。
2. 该机制的核心在于挖掘不同任务间的潜在关联性,利用已有的知识来辅助新任务的学习过程。
3. 通过构建共享的表示空间或特征提取器,实现跨任务的知识传递与泛化能力的增强。
基于表示学习的迁移方法
1. 表示学习通过将输入数据映射到低维特征空间,捕捉数据的高层语义信息,为知识迁移提供基础。
2. 常用的方法包括自编码器、变分自编码器等,这些模型能够学习到具有泛化能力的共享表示。
3. 通过调整表示空间的容量和结构,可以平衡源任务与目标任务之间的知识共享与区分。
知识迁移机制概述
知识迁移机制
多任务学习与知识迁移
1. 多任务学习通过同时训练多个相关任务,利用任务间的协同效应提升模型的泛化能力。
2. 通过共享参数或约束,多任务学习能够将一个任务中学习到的知识迁移到其他任务。
3. 该方法在资源有限的情况下尤其有效,能够显著提高小样本场景下的学习效率。
元学习与知识迁移
1. 元学习通过模拟“学习如何学习”的过程,使模型能够快速适应新任务。
2. 常用的元学习方法包括模型微调、梯度增强等,这些方法能够优化模型在少量样本上的适应能力。
3. 元学习与知识迁移的结合,能够进一步提升模型在动态变化环境中的鲁棒性。
知识迁移机制
1. 生成模型通过学习数据的分布,能够生成符合真实数据模式的样本,扩充小样本数据集。
2. 通过生成模型生成的合成数据,可以用于预训练或微调,从而增强模型的知识迁移能力。
3. 前沿的生成模型如生成对抗网络(GANs)能够生成高质量的样本,进一步优化迁移效果。
自适应知识迁移策略
1. 自适应知识迁移策略根据目标任务的特点,动态调整知识共享的程度与方式。
2. 通过任务相似度度量、注意力机制等方法,实现知识的精准迁移,避免干扰。
3. 该策略能够有效应对异构数据分布,提升模型在不同场景下的迁移性能。
基于生成模型的知识迁移
训练策略优化
小样本场景学习
训练策略优化
数据增强策略
1. 通过生成模型对少量样本进行扩展,提升样本多样性,增强模型泛化能力。
2. 结合几何变换与语义扰动,模拟真实场景中的数据变化,提高模型鲁棒性。
3. 利用对抗性样本生成技术,强化模型对边缘案例的识别能力,适应复杂环境。
损失函数优化
1. 设计加权损失函数,对稀有样本赋予更高权重,平衡类别分布不均问题。
2. 引入熵正则化,约束模型预测分布的集中性,减少过拟合风险。
3. 采用多任务学习框架,共享特征表示,提升小样本场景下的联合表征能力。
训练策略优化
元学习框架改进
1. 构建动态更新机制,根据任务序列自适应调整学习率,加速模型适应过程。
2. 结合注意力机制,强化关键样本的表征学习,提升记忆效率。
3. 利用迁移学习策略,将跨领域知识融入小样本模型,扩大有效训练数据规模。
正则化技术整合
1. 采用批量归一化与Dropout组合,缓解数据稀疏性带来的梯度消失问题。
2. 引入核范数约束,限制模型复杂度,防止过拟合高维特征空间。
3. 设计自适应正则化参数,根据任务难度动态调整惩罚力度,提升泛化性。
训练策略优化
不确定性量化方法
1. 通过贝叶斯神经网络建模,估计预测分布的不确定性,识别数据噪声。
2. 结合熵最小化目标,约束模型输出置信度,过滤不可靠预测结果。
3. 利用置信度阈值筛选伪标签,动态优化训练数据集质量。
分布式训练协同
1. 设计联邦学习机制,在保护数据隐私前提下实现多源小样本数据聚合。
2. 采用模型蒸馏技术,将多个弱小样本模型的知识迁移至单一高效模型。
3. 构建云端-边缘协同框架,利用大规模数据补充训练,提升模型全局性能。
应用领域分析
小样本场景学习
应用领域分析
智能安防监控
1. 小样本场景学习能够快速适应复杂多变的安防环境,通过少量样本即可训练出高效的监控模型,显著提升异常行为检测的准确率和实时性。
2. 结合生成模型,可生成多样化场景下的训练数据,增强模型对未知威胁的泛化能力,适用于人流密集区域、边境监控等高安全需求场景。
3. 通过融合多模态信息(如视觉、声音),系统可更精准识别潜藏风险,推动主动防御技术的演进,降低误报率至3%以下行业领先水平。
自动驾驶环境适应
1. 小样本场景学习支持车辆在动态变化的城市道路中快速学习新区域的路况特征,减少离线训练依赖,缩短模型部署周期至数小时内。
2. 基于生成模型的合成数据增强,可覆盖极端天气(如暴雨、雪雾)等低概率事件,使自动驾驶系统在边缘场景下的鲁棒性提升40%。
3. 结合多传感器融合(激光雷达、摄像头),模型可实时适配不同光照与路面条件,符合《智能网联汽车技术路线图2.0》对场景自适应能力的要求。
应用领域分析
医疗影像辅助诊断
1. 通过小样本学习快速迁移至罕见病(如早期肺癌结节)诊断,仅需10-20例标注样本即可达到专家级识别精度,缩短模型迭代周期60%。
2. 生成模型可模拟病理切片的细微纹理变化,解决医疗数据稀缺问题,使模型在欠采样(
3. 支持跨模态对比学习,融合CT与MRI数据,提升对多发性硬化症等疾病的鉴别能力,推动精准医疗向个性化方向发展。
金融欺诈实时检测
1. 小样本场景学习可动态适配新型诈骗手段(如AI换脸支付),通过1小时内处理5类欺诈样本实现模型更新,满足监管机构对响应速度的严苛标准。
2. 生成模型生成高保真交易场景,覆盖传统样本无法覆盖的异常关联模式,使模型在0.1%异常交易中的检测召回率突破90%。
3. 结合联邦学习框架,在保护用户隐私前提下实现跨机构欺诈特征迁移,助力央行数字货币(e-CNY)的智能风控体系建设。
应用领域分析
机器人自主导航
1. 小样本场景学习使服务机器人(如配送机器人)仅需3-5次探索即可适应用户新家环境,显著降低部署成本,符合《机器人产业发展白皮书》对场景泛化能力的要求。
2. 生成模型生成异构地图数据(2D平面与3D点云混合),增强机器人在光照骤变或临时障碍物环境下的定位精度,误差控制在±5cm以内。
3. 融合IMU与SLAM数据,实现多楼层无缝切换导航,支持百度Apollo机器人平台的跨区域快速适配需求,推动无人配送规模化落地。
智慧农业灾害预警
1. 小样本场景学习通过少量卫星影像样本即可识别新发病虫害(如玉米螟),预警响应时间较传统方法缩短70%,保障粮食安全体系中的早期干预能力。
2. 生成模型模拟极端气候(如霜冻、干旱)对作物生长的影响,使模型在数据不足(
3. 结合土壤湿度与气象数据,构建灾害预测-干预闭环系统,推动联合国粮食及农业组织(FAO)提出的"数字农业转型"战略在我国的实施。



