一、需求理解与核心挑战
开发高准确率的知识库问答系统,核心在于解决大语言模型(LLM)的“幻觉”问题——即模型会自信地生成与事实不符的内容。在知识密集型任务中,仅依赖LLM的参数量记忆远远不够。RAG通过将检索系统与生成模型结合,实现了“动态知识注入”,让模型基于外部知识库生成回答,从根本上提升了事实准确性。2026年的一项研究系统性地分析了LLM幻觉的产生机制,指出幻觉并非偶然故障,而是当前训练评估体系的系统性产物——模型在追求“回答听起来正确”的过程中被隐式鼓励去自信猜测,因此需要RAG这类外部架构来提供事实锚定。
当前RAG技术正从简单的“检索-生成”管道,演进为综合编排层,统一管理检索、推理、验证和治理。以下从基础到高级,提供多种系统性的方案选择。
二、方案一:基础RAG + 检索增强优化(入门级)2.1 核心架构
基础RAG采用“检索-增强-生成”三层架构,是构建高准确率知识库问答系统的起点:
2.2 关键优化策略
(1)混合检索
单一检索方式存在天然局限:向量检索擅长捕捉语义,但在精确匹配方面表现不足;关键词检索(如BM25)在精确匹配上表现出色,却缺乏语义理解能力。混合检索将两者结合,已成为现代RAG系统的基石。Google Research 2025年的一项研究表明,混合检索方法在复杂技术查询和长尾查询上的Mean Reciprocal Rank(MRR)比单一检索方式提升了15-20%。实现方式上,Late Fusion(分别检索后再融合)和Early Fusion(查询层面融合)是两种主流范式,实际应用中可根据查询特征智能选择。
(2)多路召回 + 重排序
通过多路召回可以避免单一检索方案的能力限制。在Dify+RagFlow的实践中,向量检索、关键词检索和元数据过滤的组合,使医疗设备领域实现了98%的精准匹配率。重排序则使用更强的模型(如cross-encoder)对初筛结果进行二次排序,进一步提升Top-K结果的相关性。
(3)查询改写
用户查询与知识库文档之间往往存在语义鸿沟。通过LLM对原始问题进行扩展、分解或抽象,生成多个语义等价但表述不同的查询变体,能有效提高检索的覆盖能力。HyDE(Hypothetical Document Embeddings)方法则更进一步:先用LLM生成假设性回答文档,再用该文档的向量进行检索,利用“答案与答案更相似”的特性来优化检索效果。
(4)分块策略优化
文档切片(Chunking)直接影响检索精度。Small-to-Big策略通过大小文本块映射,兼顾了检索精度与上下文丰富度。
2.3 适用场景与局限
基础RAG方案实现简单、部署成本低,适合中小规模知识库、单跳简单问答场景。但在处理多跳推理、跨文档关联等复杂任务时,准确率会受到显著限制。
三、方案二:GraphRAG + 知识图谱增强(进阶级)3.1 核心思路
传统向量RAG将文档切分为独立片段,丢失了片段之间的逻辑关系。GraphRAG通过构建知识图谱来显式建模实体和关系,在处理多文档场景下的复杂关系建模、多跳推理与知识关联方面具有显著优势。
3.2 技术架构与实现
GraphRAG的典型工作流程包含三个核心环节:基于文档构建知识图谱、对图谱进行组织总结以支持检索、通过检索数据响应用户查询。
KG-RAG(Knowledge Graph-extended RAG)进一步将知识图谱与RAG深度融合,包含问题分解模块以增强多跳信息检索和答案可解释性,利用In-Context Learning和Chain-of-Thought提示生成显式推理链。在MetaQA基准测试中,KG-RAG在多跳问题上实现了更高的准确率。
3.3 准确率实证
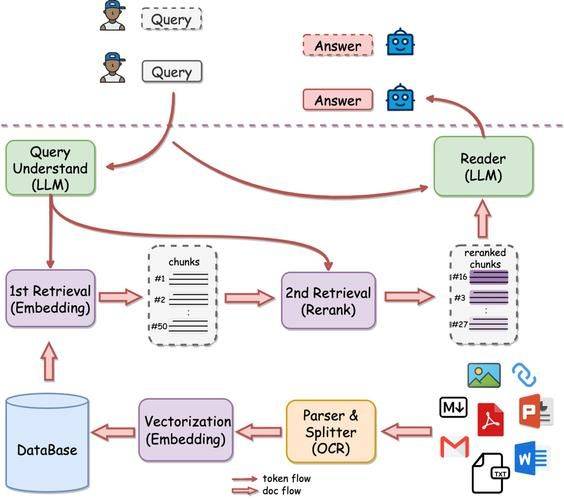
在临床问答这一对准确性要求极高的领域,基于本体论的知识图谱GraphRAG框架取得了突破性成果:
该框架在60道临床问题中正确回答了59道,幻觉率相比SOTA LLM降低了超过61个百分点。另一项金融领域案例研究表明,GraphRAG将答案精度提升了高达35%,同时减少了Token消耗。
3.4 变体方案
(1)确定性图谱 vs LLM抽取图谱
对于代码库等结构化数据,基于AST(抽象语法树)自动生成的确定性图谱,在多跳覆盖率和可靠性上显著优于LLM抽取的图谱。
(2)GC-QA-RAG
百度开发者实践方案,构建了“领域知识图谱+向量数据库”双引擎架构,在金融领域实现了92.3%的答案准确率(传统RAG为84.7%),响应延迟
(3)PolyG自适应图遍历
针对不同类型问题采用不同的图遍历策略,相比SOTA GraphRAG方法,生成质量胜率达到75%,响应速度提升至4倍。
3.5 适用场景与局限
GraphRAG特别适合:医疗诊断辅助、法律条文查询、金融分析、多跳推理问题等需要精确逻辑推理的场景。局限在于:知识图谱的构建和维护成本较高,对于频繁更新的非结构化文档,图谱的同步更新是一个工程挑战。
四、方案三:CRAG/Self-RAG + 自纠正与反馈(高级级)4.1 Corrective RAG (CRAG)
传统RAG假设检索结果总是相关的,但实际上检索可能返回不准确或不相关的内容。CRAG的核心理念在于通过预先评估检索质量并设计纠错策略,来提高系统应对检索失败的能力。
CRAG引入一个“Grader”评估器,对检索结果进行质量打分:
4.2 Self-RAG
Self-RAG更进一步,在生成过程中实时评估和调整。它通过训练LLM生成特殊的“反思Token”(Reflection Tokens),在生成过程中对检索结果的相关性、答案的支持度和实用性进行自我评估,并按需触发新的检索。
4.3 双阶段RAG优化
预回答与召回过滤的方法采用双阶段架构:第一阶段生成候选回答,第二阶段基于候选回答反向验证和过滤检索结果,从而解决用户潜在意图覆盖不足和召回质量低的问题。
4.4 适用场景与局限
适合对答案质量要求极高、允许稍高延迟的场景。CRAG和Self-RAG在多跳问答(如HotpotQA、2WikiMultiHopQA)中表现优异。局限在于:需要额外的计算开销和模型调用,实现复杂度较高。
五、方案四:Agentic RAG(前沿级)5.1 核心思路
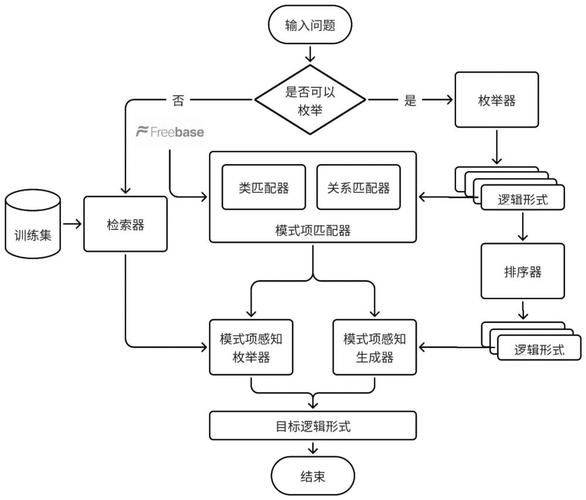
Agentic RAG将智能体(Agent)范式引入知识检索,使系统不再是静态的“检索-生成”管道,而是能够自主规划、动态路由、反思调整的“AI研究员”。
5.2 关键技术特征5.3 实证效果
Databricks的Knowledge Assistant采用Agentic架构,在问答质量上比传统RAG方法高出高达70%。腾讯乐享的Agentic知识库升级后,从一个“给员工用的知识库”升级为“能治理知识、能执行任务的知识库Agent”,能够精准拆解用户需求中的核心条件(如时间范围、行业类型、内容类别等)。
5.4 适用场景与局限
适合企业级复杂知识管理、多源异构知识库、需要自主执行任务的高端场景。局限在于:系统复杂度高,对LLM能力要求高,部署和调优门槛较高。
六、方案五:幻觉检测与验证增强(辅助方案)
无论采用哪种主方案,幻觉检测与事实性验证都是保障高准确率的重要补充层。
6.1 检索结果验证
eSapiens企业级问答系统引入了引文验证循环(Citation Verification Loop),对检索结果的引用一致性进行验证,确保回答与证据之间的关联准确无误。
6.2 声明级细粒度验证
RT4CHART框架将模型输出分解为独立可验证的声明,逐条与检索上下文进行层级验证,对每条声明标注“蕴含、矛盾或无依据”。在RAGTruth++数据集上,幻觉检测F1达到0.776,比最强基线提升了83%。
6.3 实时白盒忠实度监控
LatentAudit利用生成器中层残差流的几何特性进行实时忠实度监控,无需额外的评判模型。在PubMedQA上,该方法达到0.942 AUROC,延迟仅0.77毫秒。
6.4 中文场景的优化方向
针对中文知识库问答,需要特别注意:
七、最新技术进展(2025-2026)7.1 综述:RAG已成熟为可审计的AI设计模式
2026年《Computer Science Review》发表的系统性综述提出了“索引-检索-融合-生成”四阶段统一分类法,将RAG定位为构建可落地、可审计AI系统的成熟设计模式。综述涵盖了从基础Vector RAG到Graph RAG的完整演进路径,并绘制了Agentic RAG、Multimodal RAG、Hybrid RAG等新兴范式的发展脉络。
7.2 DCD:面向领域的受控RAG
2026年4月提出的DCD(
Domain-Collection-Document)框架,通过面向领域的设计来结构化知识和控制查询处理流程,无需修改底层语言模型,即可实现对RAG系统行为的精准控制。
7.3 GraphRetriever:文本嵌入与图遍历的融合
Meta 2026年提出的GraphRetriever系统,将文本嵌入与图遍历能力有效结合,能够处理复杂的多跳查询。
7.4 BubbleRAG:黑盒知识图谱的证据驱动RAG
针对无法预知图谱模式与结构的黑盒知识图谱场景,BubbleRAG通过证据驱动的方法解决语义实例化不确定性和路径结构不确定性问题。
7.5 SEAL-RAG:固定预算证据组装
针对多跳RAG中的上下文稀释问题,SEAL-RAG在固定预算内组装证据,在HotpotQA和2WikiMultiHopQA上对比Basic RAG、CRAG、Self-RAG等基线取得更优表现。
7.6 LLM生成元数据增强检索
2026年的一项系统研究展示了使用LLM生成元数据来增强RAG系统的实证框架,通过丰富文档元数据显著提升了检索质量。
八、方案对比与选型建议选型建议快速验证/POC:基础RAG + 混合检索 + 重排序,可选用MaxKB、Dify等成熟开源框架快速搭建高精度专业领域(医疗、法律、金融):GraphRAG方案,准确率优势明显复杂多跳推理场景:GraphRAG或Agentic RAG企业级大规模部署:Agentic RAG,兼顾准确性、可扩展性和治理能力中文场景:务必选择中文优化的Embedding模型(如源Yuan-EB 2.0、acge_text_embedding、Qwen3 Embedding)并做好中文查询改写通用准确率保障清单
无论选择哪种方案,建议从以下维度系统性地保障准确率:
优化维度
具体措施
知识库预处理
文档清洗、智能分块、元数据标注、去重去噪
检索优化
混合检索(向量+BM25)、多路召回、重排序
查询增强
查询改写、查询分解、HyDE假设文档生成
生成控制
约束解码、事实性验证、引文溯源
幻觉防御
检索结果验证、声明级验证、实时监控
持续优化